By this post, I'll start a series of blog posts about creating new IO connectors in Apache Beam.


Introduction to Beam IO
Before getting into Beam IO internals, let's take a quick look on what actually Beam pipeline codebase is. In general, logically all code, that required to run a user pipeline, can be split into 4 layers - Runner, SDK, Transforms & IO, User Code.
On the bottom level, there is a Runner code, which is responsible for all translations of user pipeline to make it possible to run on preferred data processing engine, like Apache Spark, Apache Flink, Google Dataflow, etc.
On the second level, we have a SDK code. This part of code allows to write a Beam pipeline in favourite user programming language. For the moment, Beam supports the following SDKs: Java, Python and Go. Scala is supported through 3rd party SDK called Scio.
Third level incorporates different Beam Transforms, like ParDo, GroupByKey, Combine, etc. Also, it includes all IO connectors that allow to read/write data from/to different data sources and sinks.
And, finally, on top of that, there is a forth level of Beam code called User Code. This is where actually all the business logic of user pipeline is living. Usually, it defines how and from where to read data, them how it will be transformed downstream of pipeline, and where the results will be stored in the end.

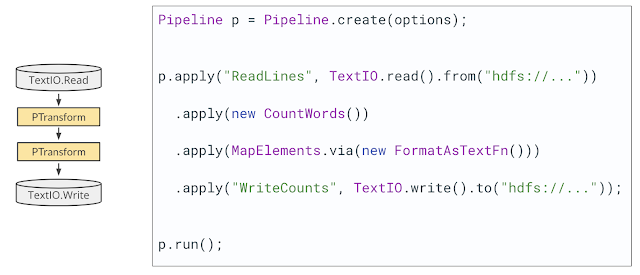
As we can see from this diagram, IO connectors and Beam transforms stay on the level of hierarchy. This is not by chance. It means that actually Beam IO is Beam transform. It can be quite complicated, provide many configuration options and different user API. It could be even consisted from several transforms (composite transform), but in the end, this is just a Beam transform.
Let's take as an example a famous WordCount task. Below, there is a Java code which consists from four different steps - two business logic transforms (CountWords and MapElements) and two IO transforms, that are implemented as a part of TextIO, and allow to read and write files using different file systems.

Beam already provides a lot of IO connectors for your choice. So, you can use them to work with different file systems, file formats, SQL and NoSQL databases, messaging and distributed queue systems, cloud and so on. Though, most of connectors are available on Java SDK.
Why would I need to write yet another IO?
There are a bunch of reasons why would you want to write your own IO connector in Beam.
BigData world is growing
Every year we see more and more storage technologies, databases, streaming system appear on the market. Unfortunately, there is no universal BigData API that every system would follow and implement. They all work differently, implement own architecture, provide own API. So, to add a support of these to Beam we will need to create a new IO connector.
We can’t use native IO of data processing engine
The logical question here could be - why not to use an IO implementation for required data processing engine? For instance, Apache Spark already provides an effective way to work with Kafka as one of the most popular messaging system. Why we need to do more?
There are several reasons for that:
- Beam is based on own model which defines how to process distributed data. So, native IOs don’t comply (or only partly comply) with Beam model and they won't work properly in Beam pipeline.
- All Beam IOs must be supported by all Beam runners. Beam-based created IOs will do this automatically.
- Developed specifically for Beam, the IOs will be much effective in terms of their performance.
Provide more features for existing IOs
Most of the data storage systems is evolving in time. So, if you need to use recent versions of their API and profit new features of this, then it could be another strong reason to extend existing connector and do such improvements.
Write own connector for specific purposes
If you use Beam for the purposes of using it with specific enterprise data storage systems with closed API, then it won't be probably possible to share created connector with open source world. In this case, you need to create own enterprise connector by your own.
Also, sometimes you want to add specific features to already existing Beam IO but it won't be accepted for different reasons into Beam project code base. In such case you will need to extend existing API by your own as well.
Way of learning
In the end, writing your own IO connector or improving existing one is a very good way to learn how Beam works internally and this is a good start point to contribute to Apache Beam and open source.
What'next?
In the next part will talk about the structure of every Beam IO:
- from which parts it consists;
- what are the difference between Bounded and Unbounded sources;
- what are the general requirements for IO code.
Stay tuned and happy Beaming!
Great article! Looking forward for your series introducing what is behind Beam IO.
ReplyDelete